
this doesn't solve the printing issue as the always infer that any char has the same size how is this printed on real windows with your character set ? A+
2011/12/14 Akihiro Sagawa sagawa.aki@gmail.com
This closes bug #10063. This check is needed for FreeType < 2.0.8, but commit 570e68b82200bdd9981b2cd8fe9e68d35bad3cb9 updated the requirement, 2.1.4 or later. And it is not useful for DBCS fonts, as they have two different width (halfwidth and fullwidth) even in monospaced font such as MS Gothic.
programs/wineconsole/user.c | 34 ++-------------------------------- 1 files changed, 2 insertions(+), 32 deletions(-)

On Wed, 14 Dec 2011 19:35:34 +0100, Eric Pouech wrote:
this doesn't solve the printing issue as the always infer that any char has the same size how is this printed on real windows with your character set ?
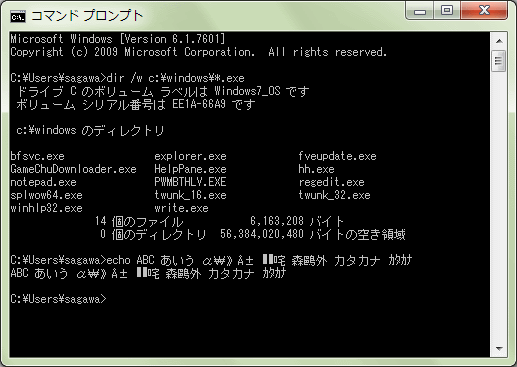
See the attachment, please. It was taken in my Windows 7 PC with Japanese Terminal font. Most of Japanese characters take up the double width of the ASCII characters. For example, the first Japanese character (KATAKANA LETTER DO, U+30C9) is as same width as `:¥' (=two halfwidth characters).
Unicode Standard Annex #11, East Asian Width (*), may help understanding East Asian character width. * ... http://www.unicode.org/reports/tr11/
In the document, some characters are defined as ambiguous. And its recommendation is that ambiguous characters always map to fullwidth characters when mapping Unicode to East Asian legacy characters.
But actually it depends on locales or encodings. For instance, as shown in the bottom echo line in the snapshot, U+E1 (LATIN SMALL LETTER A WITH ACUTE) is halfwidth and U+B1 (PLUS-MINUS SIGN) is fullwidth in Japanese environment.
In my humble opinion, printing issue is not good especially for users. But, as far as I know, it doesn't occur in ASCII characters. And it is better than showing the error message, "Couldn't find a decent font, aborting," at starting up.
{kind=link}
Le 15/12/2011 17:18, Akihiro Sagawa a écrit :
On Wed, 14 Dec 2011 19:35:34 +0100, Eric Pouech wrote:
this doesn't solve the printing issue as the always infer that any char has the same size how is this printed on real windows with your character set ?
See the attachment, please. It was taken in my Windows 7 PC with Japanese Terminal font. Most of Japanese characters take up the double width of the ASCII characters. For example, the first Japanese character (KATAKANA LETTER DO, U+30C9) is as same width as `:¥' (=two halfwidth characters).
Unicode Standard Annex #11, East Asian Width (*), may help understanding East Asian character width.
In the document, some characters are defined as ambiguous. And its recommendation is that ambiguous characters always map to fullwidth characters when mapping Unicode to East Asian legacy characters.
But actually it depends on locales or encodings. For instance, as shown in the bottom echo line in the snapshot, U+E1 (LATIN SMALL LETTER A WITH ACUTE) is halfwidth and U+B1 (PLUS-MINUS SIGN) is fullwidth in Japanese environment.
In my humble opinion, printing issue is not good especially for users. But, as far as I know, it doesn't occur in ASCII characters. And it is better than showing the error message, "Couldn't find a decent font, aborting," at starting up.
as pointed out in http://blogs.msdn.com/b/buckh/archive/2005/09/11/463427.aspx#2250089 those Japanese characters need to be stored in two adjacent "cells" in the console infrastructure code...
your patch will actually print them on top of two cells, while it's going to be stored only in one... it would then lead to making all the output (and internal encoding) be wrong
A+
-
 Akihiro Sagawa
Akihiro Sagawa -
 Eric Pouech
Eric Pouech